Load Balancing 101: چگونه به High Availability دست یابیم

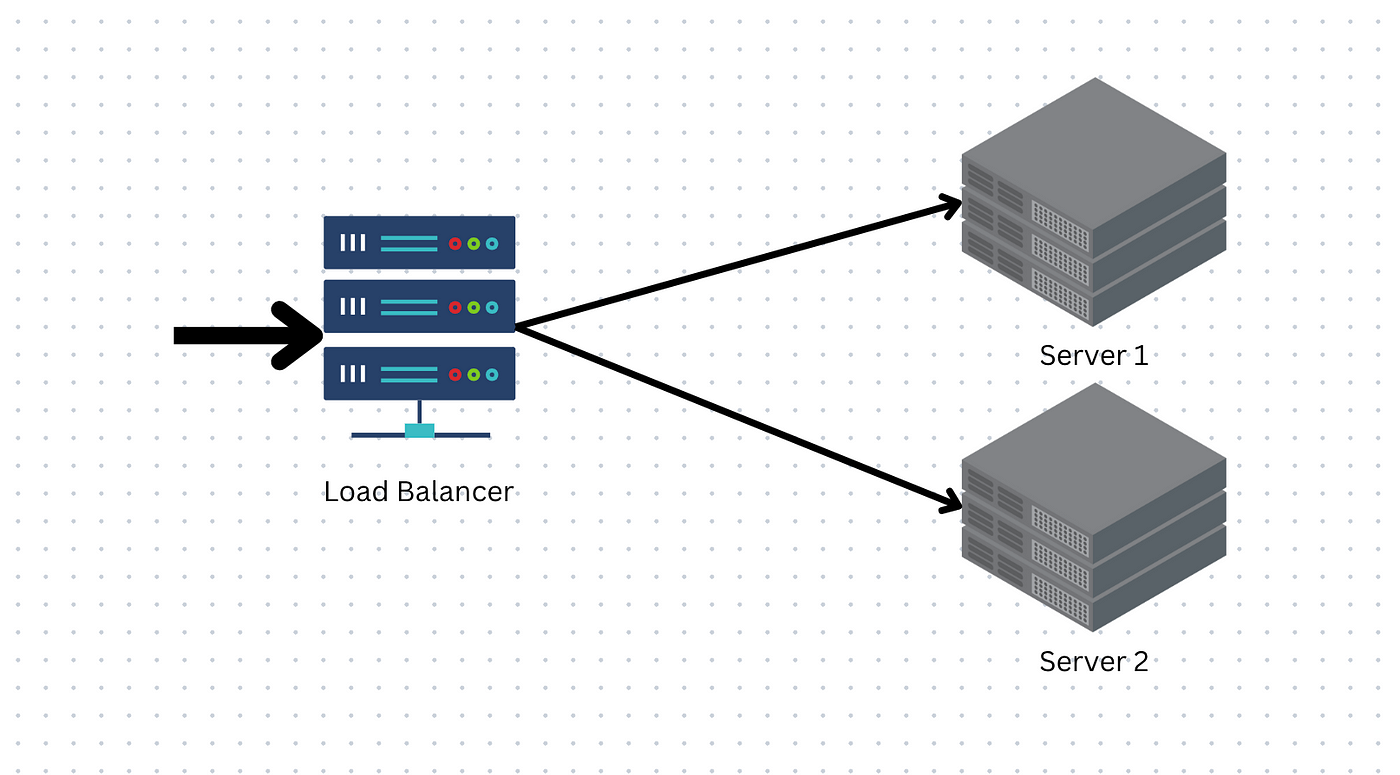
در دنیای Cloud و DevOps، دسترسپذیری بالا (High Availability) و پایداری سرویسها از اهمیت ویژهای برخوردار است. یکی از ابزارهای کلیدی برای اطمینان از این پایداری، استفاده از Load Balancing است. در این مقاله به طور عمیق به مفهوم Load Balancing، انواع آن، الگوریتمهای توزیع بار، و چگونگی پیادهسازی آن در زیرساختهای پیچیده میپردازیم.
Load Balancing: تعریف و کارکرد
Load Balancing به معنای توزیع هوشمندانه ترافیک شبکه یا درخواستهای application بین چندین server یا backend instance است. هدف از این کار، افزایش کارایی، جلوگیری از bottlenecks و تضمین fault tolerance است. در زیر به دو لایه اصلی Load Balancing میپردازیم:
- Layer 4 (Transport Layer) Load Balancing: این نوع load balancing ترافیک را در سطح TCP یا UDP توزیع میکند. مثالهایی شامل Nginx Stream Load Balancer و AWS Network Load Balancer هستند. در این حالت، Load Balancer تنها به IP address و port توجه میکند.
- Layer 7 (Application Layer) Load Balancing: این نوع Load Balancer ترافیک را بر اساس محتوا، یعنی HTTP headers، URLs، یا حتی session data توزیع میکند. مثالهایی مانند HAProxy، Nginx، و AWS Application Load Balancer در این دسته قرار میگیرند. Layer 7 Load Balancers میتوانند تصمیمات پیچیدهتری در مورد نحوه توزیع درخواستها بگیرند.
الگوریتمهای توزیع بار
Load Balancers از چندین algorithm برای توزیع ترافیک استفاده میکنند که هر یک برای نیازهای خاصی بهینه شده است:
- Round Robin: یکی از سادهترین الگوریتمها که درخواستها را به ترتیب بین backend servers توزیع میکند. برای محیطهای با ترافیک مشابه مناسب است، اما در محیطهای با ترافیک سنگین بهینه نیست.
- Least Connections: ترافیک را به سروری هدایت میکند که کمترین تعداد active connections را دارد. این الگوریتم برای long-running connections مانند database queries ایدهآل است.
- IP Hash: این الگوریتم با استفاده از IP address کلاینت، یک سرور مشخص را برای هر client انتخاب میکند. این روش برای اطمینان از ثبات اتصال در session-based applications (مثلاً e-commerce یا online banking) مناسب است.
- Weighted Round Robin: در این روش، به هر server یک وزن اختصاص داده میشود و سرورهای قویتر ترافیک بیشتری دریافت میکنند. این روش برای heterogeneous environments که سرورهایی با منابع متفاوت دارند، مناسب است.
Health Checks و Fault Tolerance
یکی از مهمترین قابلیتهای Load Balancer ها health check است. Load Balancer ها به طور مداوم سلامت backend servers را بررسی میکنند و در صورتی که یکی از سرورها دچار مشکل شود، آن را از traffic rotation خارج میکنند. این کار به دو روش انجام میشود:
- Active Health Checks: به طور دورهای HTTP requests یا TCP pings به سرورهای پشت Load Balancer ارسال میشود تا وضعیت آنها بررسی شود.
- Passive Health Checks: بر اساس خطاهای زمانی که درخواستها به سرور ارسال میشود، Load Balancer متوجه میشود که سرور خراب است.
Load Balancing در Cloud
در زیرساختهای Cloud، Load Balancing به عنوان یک سرویس managed ارائه میشود که نیازی به پیادهسازی دستی ندارد. در ادامه چند سرویس رایج در Cloud providers را معرفی میکنیم:
- AWS Elastic Load Balancer (ELB): شامل Application Load Balancer (ALB) برای ترافیک HTTP/HTTPS و Network Load Balancer (NLB) برای ترافیک TCP است. AWS ELB به طور خودکار scales میشود و با سایر سرویسهای AWS مثل Auto Scaling Groups یکپارچه است.
- Google Cloud Load Balancer: یک سرویس global است که از Layer 4 و Layer 7 Load Balancing پشتیبانی میکند و برای high-performance applications مناسب است.
- Azure Load Balancer: برای Layer 4 و Application Gateway برای Layer 7 Load Balancing استفاده میشود و به راحتی در زیرساختهای Azure قابل پیادهسازی است.
پیادهسازی Load Balancer با Nginx
http {
upstream backend_servers {
server 192.168.1.101;
server 192.168.1.102;
server 192.168.1.103;
}
server {
listen 80;
location / {
proxy_pass http://backend_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}نتیجهگیری
استفاده از Load Balancing در زیرساختهای Cloud و On-Prem یکی از ضروریترین تکنیکها برای دستیابی به High Availability و Scalability است. با انتخاب الگوریتم مناسب و استفاده از ابزارهایی مثل Nginx، HAProxy، یا سرویسهای Cloud-based مثل AWS ELB، میتوانید پایداری و عملکرد بهتر در سرویسهایتان تضمین کنید. همچنین استفاده از health checks و active monitoring باعث میشود که در صورت بروز خطا، سیستم به صورت failover به کار خود ادامه دهد.